Google Search Console is an amazing tool that provides invaluable search data by real users directly from Google. While the charts and tables are friendly to work with, a large part of the data is not accessible from the UI.
The only way to get to this hidden data is to use the API and extract all that valuable search data that is available to you – if you know how. This is possible with regular expressions.
Here’s how you can maximize the Google Search Console API using regular expressions, according to Eric Wu, VP of Product Growth at Honey, a PayPal Company, who spoke at SMX Advanced.
Diagnosing SEO issues with GSC
Working on a website experiencing stagnant or declining growth or a core update drop?
Most SEO professionals turn to Google Search Console (GSC) to diagnose such issues.
(Or if resources permit, you may even use a paid tool like Ryte or build your own platform.)
Fortunately for the SEO community, there’s no shortage of Looker Studio dashboards (formerly Google Data Studio) useful for GSC analysis, including:
- Aleyda Solis’ free dashboard, which uses GSC data to easily identify potential rankings changes in recent days from the Google Core Update.
- Google’s search traffic monitoring dashboard, which now pulls Discover and Google News traffic data.
- Hannah Butler’s Search Console Explorer Studio. (And if you want to manipulate GSC data hands-on and find quick insights, you can use Butler’s Search Console Explorer Sheet.)
Dashboards allow SEOs to look at an overview of different trends as opposed to using GSC and doing multiple clicks to get to the data you need.
But if you’re analyzing enterprise sites, you can run into some roadblocks.
- Looker Studio and Google Sheets both load slowly, especially when you’re dealing with large sites.
- GSC’s interface has a 1,000-row export limit.
- GSC has a huge sampling problem. Enterprise SEO teams miss 90% of their GSC keywords, according to Similar.ai. And if you know how to extract the data, you can actually get 14x the keywords.
Overcoming GSC’s sampling problem
Explorer for Search is another tool that you can use for GSC analysis. From Noah Learner and the team at Two Octobers, it is built with data pipelines using GSC’s API which then outputs data to BigQuery (basically bypassing Google Sheets and downloading CSV files), and then visualizes information with Data Studio.
With this, you can have confidence that you’re getting to almost all the data.
There’s still a caveat due to GSC’s sampling problem, especially for large, ecommerce sites with lots of different categories. GSC won’t necessarily show all the data that’s coming in from those directories.
After conducting various tests to get the most data out of the GSC API, the Similar.ai team discovered a way to close the GSC sampling gap.
They found that by adding more subdirectories as different profiles within your GSC dashboard, you can extract even more data as Google gives you more information at that lower level.

For example, if you’re looking at example.com/televisions and you add “televisions” as a subdirectory in your GSC profile, Google will give you only the keywords and the click information for that subdirectory and down.
And by adding a lot of these different subdirectories, you can extract a lot more information.
That solves the sampling problem, but you can get even more data by using regular expressions.
Getting more GSC data with regular expressions
Regular expression, or regex, is a powerful tool to understand your data.
In April 2021, Google added regex support to GSC – giving SEOs more ways to slice and dice organic search data.
A lot of times, data is not useful unless you can comprehend it. And regex helps to extract actionable insights from GSC’s rich data.
But as powerful as it may be, regex can be difficult to learn.
The best place to understand and dive deep into regular expressions is Google’s official documentation on GitHub. (Google uses RE2 in its products, which is a flavor of regular expression.)
While regex is available in all kinds of different programming languages, you’ll find it almost everywhere even to those who are modifying .htaccess files.
In the next few sections are use cases for leveraging regex for GSC.
Regex informational queries
When looking at actual informational search queries in GSC, you typically want to understand:
- How are people actually coming to your site?
- What questions are they extracting?
Looking at those things from a one-off standpoint, within GSC can be difficult.
You’re always searching for the words “what,” “how,” “why” and then “when.”
There are a couple of ways to make extracting informational queries less tedious with regex.
Daniel K. Cheung shared a regex string that will show you all queries containing “what,” “how,” “why” and “when” that either got a click or an impression:
"what|how|why|when"
And this regex string shared by Steve Toth takes the previous example up a notch:
^(who|what|where|when|why|how)[" "]
You can use this string if you want to capture question-based queries that start with either “who,” “what,” “where,” “when,” “why” and “how” and then followed by a space.
This is a great list to use when you’re looking for any type of word that would start a question:
- are, can, can’t, could, couldn’t, did, didn’t, do, does, doesn’t, how, if, is, isn’t, should, shouldn’t, was, wasn’t, were, weren’t, what, when, where, who, whom, whose, why, will, won’t, would, wouldn’t
Putting all this into regex form would look something like this:
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
In this 178-character string:
- You have the caret (
^) which tells you the query needs to begin with this word: - The words are separated with pipes (
|) instead of commas. - All the words are wrapped in parentheses.
- There’s a backslash and the “s” (
\s) which denotes a space after the word.
This is good, but can also get tedious to do.
Below, Wu simplified the previous list of words to be more regex-friendly and shorter which is ideal for copying and pasting. Maintaining it this way also helps with efficiency.
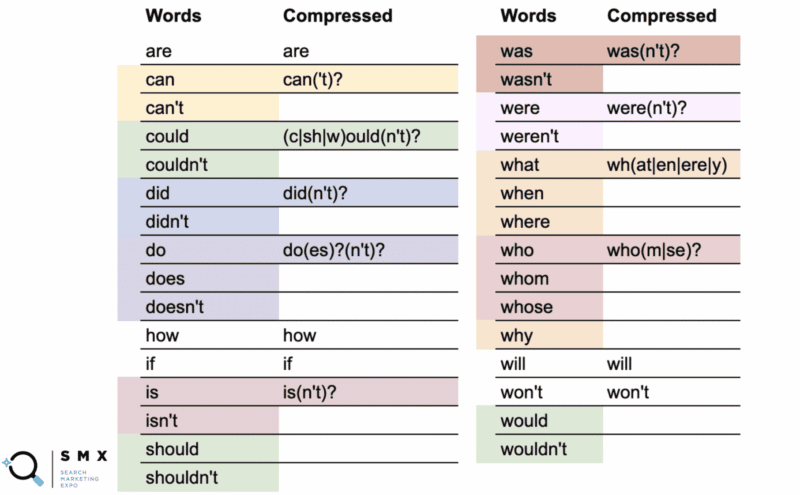
In the first column are the normal words and in the second column, the compressed regex.
For instance, the word “can” uses the compressed version can(‘t)?.
What the question mark indicates is that anything within the parentheses is optional. The compressed syntax allows you to cover both the word “can” and “can’t.”
More interestingly, you can do this with could/couldn’t, should/shouldn’t, and would/wouldn’t where the -ould part of the words is the common base, like (c|sh|w)ould(n’t)?. This short string covers all six of those cases.
While simplifying that long list of words turned the string less readable, what’s great is that it fits more into the regex field and allows you to copy-paste easier.
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
If you go a step further, you can compress it even more. In this case, Wu reduced the character count from 135 to 113 characters.
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
Regular expressions can get really complicated. If you’re getting a regex string from someone else and would like to disambiguate what is doing what, you can use Regexper to help you visualize it.

Below you’ll see a comparison of the different regex string versions. It’s easier to maintain the first one, and obviously harder to maintain and read the last one.

But sometimes character count really will matter especially when you have longer regular expressions.
Regex filter limits for GSC is 4,096 characters, according to Google Search Advocate Daniel Waisberg.
That would seem quite a bit. However, if you have an ecommerce site and have to add domain names, subdomains or longer directories, you’ll most likely hit that limit.
Regex branded queries
Another instance where you may start hitting the regex character limit in GSC is when you use it for branded queries.

When you think about all the different types of misspellings of a brand name that a person could type, you’ll quickly run into that 4,096 character count. For instance:
- aamaung, damsung, mamsang, sam sung, samaung, samdung, samesung, sameung, samgsung, samgung, samsang, samsaung, samsgu, samshgg, samshng, samsing, samsnug, samssung, samsu, samsuag, samsubg, samsubng, samsug, samsumg, samsumng, samsun g, samsunb, samsund, samsund, samsunh, samsunt …
This is where understanding regex helps. With this string, you can capture the brand name “samsung” along with misspellings:
(s+|a|d|z)[a-z\s]{1,4}m?[a-z\s]{1,6}(m|u|n|g|t|h|b|v)
A lot of times, people will misspell the middle parts of the word. But in general, they get the format and length right and you can approach your syntax this way.
For brand query misspellings, consider the following:
- Main letters that make up the brand query.
- Consonants.
- Letters surrounding hard consonants.

In red are the hard consonants that people typically don’t miss when they’re typing in a brand name. These are the main letters that make up that particular brand. For “samsung”, the “s” in the beginning, the ”m” in the middle, and then “n” and “g” at the end.
The blue letters surrounding those main consonants on the keyboard are the ones people typically mistype. In the example, around “s”, you see the “a”, “d” and “z”. (While the layout is different for international keyboards, the concept is still the same.)
The regex string above captures all the possible variants of “samsung.”
The other major trick here is in [a-z\s]{1,4}.
In regex form, this basically says, “I want to match any letter “a” to “z”, or a space, one to four times.”
This captures all those weird misspellings that can happen in the middle of a brand query – where a person can potentially hit the same key multiple times or accidentally press space.
Additionally, the brand name is a certain length (“samsung” has seven characters). People likely won’t end up typing 20–50 characters.
So in this regular expression, we’re guessing that between “s” and “m” in “samsung,” someone’s going to mistype 1–4 characters. And then from “m” to “g” at the end, they’ll mistype 1–6 characters, with spaces included.
Adding all this allows you to capture the many variations of a branded query comprehensively.
The other thing to note is that the brand name could appear in different parts of the query.

So we need to make sure that the brand name itself, is captured. It should either be:
- At the start of the query.
- In the middle of the query (thus surrounded by spaces).
- Or at the end of the query.
The regular expression for this is as follows:
(^|\s)(s+|a|d|z)[a-z\s]{1,4}m?[a-z\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
This captures all queries where the brand name “samsung” is either at the start, middle or end.
- Start of string =
^ - Surrounded by spaces =
\s - End of string =
$
JC Chouinard’s post, Regular Expressions (RegEx) in Google Search Console, dives even deeper into regex examples.
Regex and the GSC API in action
Regular expressions came in useful for Wu and his team when they worked with a client that encountered traffic drops following a core update.
After looking at the ecommerce site’s different issues, they discovered that the problem resided in some product detail pages.
They needed to segment pagetypes for analysis in GSC. But this was a complex task because of the different URL structures for U.S. and international products.

The site’s international product URLs included language and country codes, whereas U.S. product URLs did not.
Even using regex syntax was tricky because letters and dashes exist in the product slug, categories and subcategories. Additionally, they needed to filter out the international product URLs to capture only U.S. pages.
To get all U.S. product landing + detail pages (not i18n pages), they came up with the following regex strings:
Include: /([^/]+/){1,2}p?
Exclude: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
Here’s a breakdown:

The team wanted to match the category, the subcategory and all the products so they included:
- Any character that’s not a slash =
[^/]+ - 1 or 2 directories =
/){1,2} - Sometimes followed by a product slug =
p?
A caret (^) typically means the start of the string. But when it’s inside brackets (as in [^/]), it indicates a negation (i.e., “not anything within this box”).
So this string /([^/]+/){1,2}p? means “I want any number of characters that is not a slash, leading up to a slash (which denotes the directory), and sometimes followed by the letter ‘p’ (the prefix for product slugs).”
At the same time, the team didn’t want to match the country and language combination which also contained letters and dashes, so they excluded:
- Any 2 letter directory =
[a-zA-Z]{2} - 2 letter + 2 letter lang-country combo =
[a-zA-Z]{2}-[a-zA-Z]{2}
Creating a regular expression to match all the language and country codes on their own would be tedious because of all the possible combinations, so they were unable to approach this the way did for informational queries (where every single type of combination was excluded).
But even after creating these regex strings, they had a problem.
In Google Search Console, there’s only one field to paste a regex string. You’ll have to choose either Matches regex or Doesn’t match regex – you can’t use both at the same time.

This is where the GSC API came in handy as it allows joining regex strings.
In the Google Search Console API documentation, there’s a Try it now link.

Once clicked, it will open up a console that allows you to select a site and make your API request through the web view.

But to better manage API queries, Wu recommends using Postman on the desktop or Paw (which is native to Mac).
Postman allows you to create queries and save them for later. And if you have access to other sites, you don’t have to create a new query each time. You just simply change out the site name with a variable and then make multiple requests.

Paw, on the other hand, is much easier to look through and utilize.

To access the API, you’ll need to get your API keys. (Here’s a helpful tutorial from Chouinard.)
Once you get this info, you’ll have your client ID and client secrets, which you’ll add to your OAuth 2.0 authentication within either Postman or Paw.
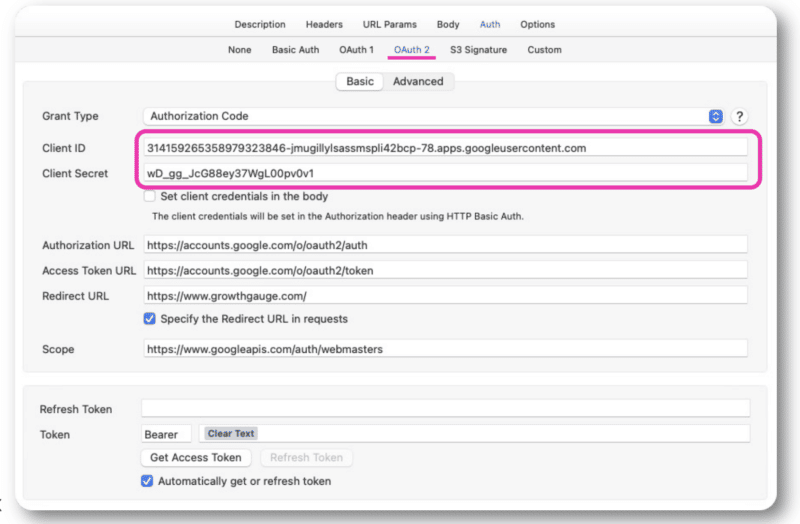
From there, you’ll be able to sign in with your normal account.
Wu mainly made GSC API requests using the regex strings in Paw. The query is entered in the middle of the interface.
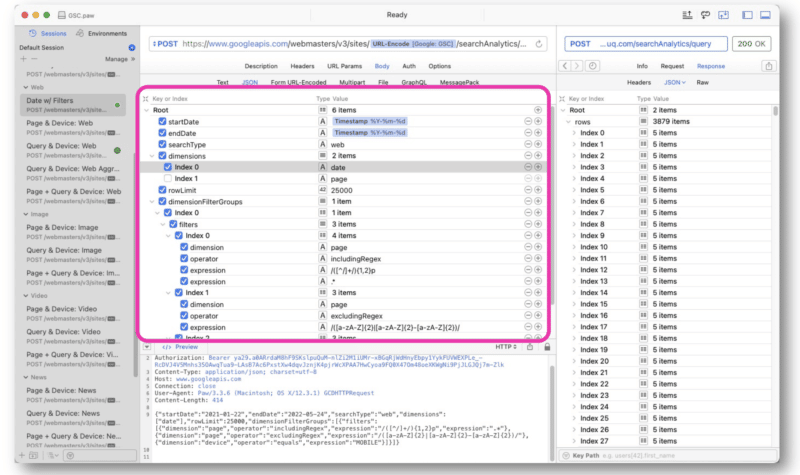
The response from Google is similar to that of the GSC API web view. The data can then be exported for processing.
Since the data is in JSON, the information can be messy and hard to read.

For this, you can use a free and open-source command-line JSON processor called JQ to pretty-print the information.

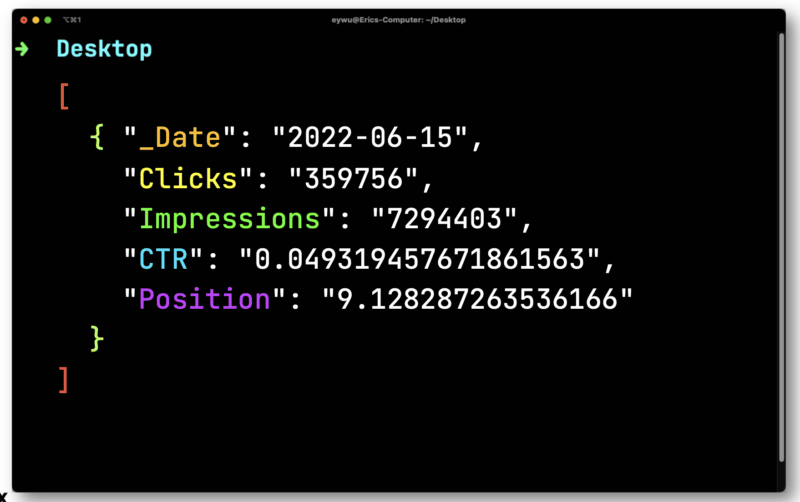
The data is not that useful until you get it into a spreadsheet. Pipe in the file you’ve exported from Paw to JQ. Open it and then iterate over each row – saving each element so you can output them to a CSV.

Here, you’ll need to convert clicks and impressions which are floats (a number that has a decimal place). Both need to be converted into strings compatible with a CSV.
JQ will then output the following much-simpler format.
Next, you’ll use Dasel to take this format and then make it into a CSV.
And here’s the end result.

What’s amazing for Wu’s team is that they were able to use the Google Search Console API and regular expressions to:
- Filter out all the international queries and look at just the U.S. where they were having the main issues.
- Identify the days the site was having issues.
Watch: Getting the most out of the Google Search Console API
Below is the complete video of Wu’s SMX Advanced presentation.
The post How to get the most out of the Google Search Console API using regex appeared first on Search Engine Land.
No comments:
Post a Comment