Getting backlinks is one of the most challenging and time-consuming tasks in SEO. So how do you get started on creating a successful outreach program that brings in quality links?
Join Purelinq’s Kevin Rowe, who will walk you through creating a scalable outreach program to create a natural link profile, meet minimum quality requirements and drive maximum impact.
What you’re about to read is not actually from me. It’s a compilation of PPC-specific lessons learned by those who actually do the work every day in this age of machine learning automation.
Before diving in, a few notes:
These are “lessons already learned.”
Things change (the platforms giveth, taketh, and sometimes just plain change the way campaigns need to be managed).
Below are a mix of strategic, tactical, and “mindset-approach” based lessons.
Lesson 1: Volume is critical to an automated strategy
It’s simple, a machine cannot optimize toward a goal if there isn’t enough data to find patterns.
For example, Google Ads may recommend “Maximize Conversions” as a bid strategy, BUT the budget is small (like sub $2,000/mo) and the clicks are expensive.
In a case like this, you have to give it a Smart Bid strategy goal capable of collecting data to optimize towards.
So a better option might be to consider “Maximize Clicks” or “Search Impression Share”. In small volume accounts, that can make more sense.
Lesson 2: Proper learning expectations
The key part of “machine learning” is the second word: “learning.”
For a machine to learn what works, it must also learn what doesn’t work.
That part can be agonizing.
When launching an initial Responsive Search Ad (RSA), expect the results to underwhelm you. The system needs data to learn the patterns of what works and doesn’t.
It’s important for you to set these expectations for yourself and your stakeholders. A real-life client example saw the following results:
RSA Month 1: 90 conversions at $8 cost per.
RSA Month 2: 116 conversions at $5.06 cost per.
As you can see, month two looked far better. Have the proper expectations set!
Lesson 3: Old dogs need to learn new tricks
Many of us who’ve been in the industry a while weren’t taught to manage ad campaigns the way they need to be run now. In fact, it was a completely different mindset.
For example, I was taught to:
Think of the “ad as a whole” as opposed to thinking about individual snippets and the possible combinations and how they might combine to make creative that performs.
A/B testing using the Champion/Challenger methodology where the “control” is always the top performing creative and you can only alter one specific element at a time otherwise you have no idea what actually caused the performance shift. Now, in a high-volume campaign, machine learning may determine that one assembly of creative snippets performs better for an audience subset while another variation performs better for a different one.
Lesson 4: Stay on top of any site changes
Any type of automation relies on proper inputs. Sometimes what would seem to be a simple change could do significant damage to a campaign.
Some of those changes include:
Change to the URL on a “thank you page”
Addition of another call to action on the landing page
Plugin or code that messes up page load
Addition or removal of a step in the conversion path
Replacing the hosted video with a YouTube or Vimeo embed
Those are just a few examples, but they all happened and they all messed with a live campaign.
Just remember, all bets are off when any site change happens without your knowledge!
Lesson 5: Recommendations tab
The best advice to follow regarding Recommendations are the following:
Take them with a critical eye. Remember this is a machine that doesn’t have the context you do. Give the recommendations a look.
Be careful where you click! It’s easy to implement a recommendation, which is great unless you make an unintentional click.
Lesson 6: Closely watch Search Impression Share, regardless of your goal
Officially defined as “the impressions you’ve received on the Search Network divided by the estimated number of impressions you were eligible to receive,” Search Impression Share is basically a gauge to inform you what percentage of the demand you are showing to compete for.
This isn’t to imply “Search Impression Share” is the single most important metric. However, you might implement a smart bidding rule with “Performance Max” or “Maximize Conversions” and doing so may negatively impact other metrics (like “Search Impression Share”).
That alone isn’t wrong. But make sure you’re both aware and OK with that.
Lesson 7: Stay on top of changes (to the ad platforms)
Sometimes things change. It’s your job to stay on top of it. For smart bidding, “Target CPA” no longer exists for new campaigns. It’s now merged with “Maximize Conversions”.
Smart Shopping and Local Campaigns are being automatically updated to “Performance Max” between July and September 2022. If you’re running these campaigns, the best thing you can do is to do the update manually yourself (one click implementation via the “recommendations” tab in your account).
Why should you do this?
Eliminate any surprises due to an automatic switchover. There probably wouldn’t be any, but you never know and it’s not worth the risk.
Reporting will be easier as YOU will pick when it happens so you can note it properly
There’s a general peace of mind when you are the one to make the update happen at a time of your choosing.
Lesson 8: Keep separate records of your rules
This doesn’t need to be complicated. Just use your favorite tool like Evernote, OneNote, Google Docs/Sheets, etc. Include the following for each campaign:
The what (goals, smart bidding rules, etc.)
Why (Your justification for this particular setup)
There are three critical reasons why this is a good idea:
You deserve to take a holiday at some point and the records are helpful for anyone who may be watching your accounts.
At some point, you’re going to be questioned on your approach. You’ll get questions like “Why, exactly did you set it up that way?” Having the record readily available come in handy.
It’s helpful for you to remember. Anytime you can get something “out of your head” and properly documented somewhere, it’s a win!
Lesson 9: Reporting isn’t always actionable
Imagine you’re setting up a campaign and loading snippets of an ad. You’ve got:
3 versions of headline 1
4 versions of headline 2
2 versions of headline 3
3 versions of the first description
2 versions of the second description
The list goes on…
Given the above conditions, do you think it would be at all useful to know which combinations performed best? Would it help you to know if a consistent trend or theme emerges? Wouldn’t having that knowledge help you come up with even more effective snippets of an ad to test going forward?
Well, too bad because that’s not what you get at the moment.
Lesson 10: Bulk upload tools are your friend
If you run a large volume account with a lot of campaigns, then anytime you can provide your inputs in a spreadsheet for a bulk upload you should do it. Just make sure you do a quality check of any bulk actions taken.
Menu in Google Ads where “Bulk Actions” is located
Lesson 11: ALWAYS automate the mundane tasks
Few things can drag morale down like a steady stream of mundane tasks. Automate whatever you can. That can include:
Pausing low performing keyword
Pause low performing ads
Scheduling
Bid adjustments based on success metrics (example Maximize Conversions)
Bid adjustments to target average position
Bid adjustments during peak hours
Bid to impression share
Controlling budgets
Lesson 12: Innovate beyond the default tools
To an outsider, managing an enterprise level PPC campaign would seem like having one big pile of money to work with for some high-volume campaigns. That’s a nice vision, but the reality is often quite different.
For those who manage those campaigns, it can feel more like 30 SMB accounts. You have different regions with several unique business units (each having separate P&L’s).
The budgets are set and you cannot go over it. Period.
You also need to ensure campaigns run the whole month so you can’t run out of budget on the 15th.
Below is an example of a custom budget tracking report built within Google Data Studio that shows the PPC manager how the budget is tracking in the current month:
Lesson 13: 10% rule of experimentation
Devote 10% of your management efforts (not necessarily budget) to trying something new.
Try a beta (if you have access to it), a new smart bidding strategy, new creative snippets, new landing page, call to action, etc.
Lesson 14: “Pin” when you have to
If you are required (for example by legal, compliance, branding, executives) to always display a specific message in the first headline, you can place a “pin” that will only insert your chosen copy in that spot while the remainder of the ad will function as a typical RSA.
Obviously if you “pin” everything, then the ad is no longer responsive. However, it has its place so when you gotta pin, you gotta pin!
Lesson 15: The “garbage in, garbage out” (GIGO) rule applies
It’s simple: The ad platform will perform the heavy lifting to test for the best possible ad snippet combinations submitted by you to achieve an objective defined by you.
The platform can either perform that heavy lifting to find the best combination of well-crafted ad snippets or garbage ones.
Bottom line, an RSA doesn’t negate the need for skilled ad copywriting.
Lesson 16: Educate legal, compliance, & branding teams in highly regulated industries
If you’ve managed campaigns for an organization in a highly regulated industry (healthcare, finance, insurance, education, etc.) you know all about the legal/compliance review and frustrations that can mount.
Remember, you have your objectives (produce campaigns that perform) and they have theirs (to keep the organization out of trouble).
When it comes to RSA campaigns, do yourself a favor and educate the legal, compliance, and branding teams on:
The high-level mechanics
Benefits
Drawbacks
Control mechanisms available
How it affects their approval process
Lesson 17: Don’t mistake automate for set and forget
To use an automotive analogy, think of automation capabilities more like “park assist” than “full self driving.”
For example, you set up a campaign to “Bid to Position 2” and then just let it run without giving it a second thought. In the meantime, a new competitor enters the market and showing up in position 2 starts costing you a lot more. Now you’re running into budget limitations.
Use automation to do the heavy lifting and automate the mundane tasks (Lesson #11), but ignore a campaign once it’s set up.
Lesson 18: You know your business better than the algorithm
This is related to lesson #5 and cannot be overstated.
For example, you may see a recommendation to reach additional customers at a similar cost per conversion in a remarketing campaign. Take a close look at the audiences being recommended as you can quickly see a lot of inflated metrics – especially in remarketing.
You have the knowledge of the business far better than any algorithm possibly could. Use that knowledge to guide the machine and ensure it stays pointed in the right direction.
Lesson 19: The juice may not be worth the squeeze in some accounts
By “some accounts,” I’m mostly referring to low-budget campaigns.
Machine learning needs data and so many smaller accounts don’t have enough activity to generate it.
For those accounts, just keep it as manual as you can.
Lesson 20: See what your peers are doing
Speak with one of your industry peers, and you’ll quickly find someone who understands your daily challenges and may have found ways to mitigate them.
Attend conferences and network with people attending the PPC track. Sign up for PPC webinars where tactical campaign management is discussed.
Participate (or just lurk) in social media discussions and groups specific to PPC management.
Lesson 21: Strategic PPC marketers will be valuable
Many of the mundane tasks (Lesson #11) can be automated now, thus eliminating the need for a person to spend hours on end performing them. That’s a good thing – no one really enjoyed doing most of those things anyway.
As more “tasks” continue toward the path of automation, marketers only skilled at the mundane work will become less needed.
On the flipside, this presents a prime opportunity for strategic marketers to become more valuable. Think about it – the “machine” doing the heavy lifting needs guidance, direction and course corrective action when necessary.
That requires the marketer to:
Have a thorough understanding of business objectives in relation to key campaign metrics.
Guide the organization’s stakeholders setting overall business strategy on what’s possible with PPC.
See how the tactical capabilities to manage a campaign can further a specific business objective.
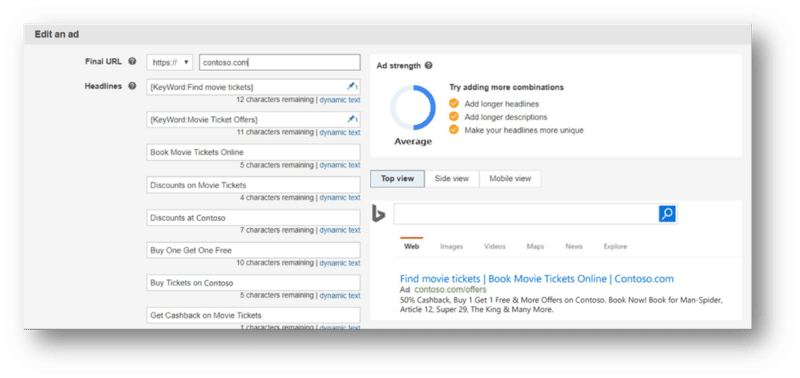
Responsive Search Ads – RSA for short – are not the new kids on the block. RSAs have been a part of the PPC ecosystem for a few years. That being said, RSAs have been a hot topic in 2022. Why all the hubbub about them now?
This summer, the preceding ad type, Expanded Text Ads, is being deprecated. This puts Responsive Search Ads front and center for advertisers as the singular text ad type for search campaigns. Let’s dig in a little bit deeper on RSAs, the change and how you can maximize your potential with RSAs.
Why RSAs matter
Responsive Search Ads are all about serving the right message at the right time. RSAs are a flexible ad experience that show more customized content to reach your customers. These ads adapt your text ads to closely match what someone is searching for when they search for it.
Further, RSAs can help to reduce bulky operations and save time. Advertisers provide up to 15 headlines and up to four descriptions. All of these components can create over 40,000 possible ad permutations! Find efficiency in evaluating ads through A/B tests and automatically determine what creative content works best with different queries.
Expanded Text Ad deprecation
The deprecation of Expanded Text Ads is coming in two waves this summer. The first wave was for Google Ads on June 30th. The second wave will be Microsoft Advertising. As of August 29th, advertisers will no longer be able to create new Expanded Text Ads.
On both platforms, previously existing Expanded Text Ads will continue to serve. Note that though you can toggle these ads on and off, you will no longer be able to edit the ads.
Maximize your potential with RSAs
How can you maximize your potential with RSAs? First and foremost, get started by launching RSAs alongside Expanded Text Ads today if you haven’t already. Here are some additional best practices to consider when working with RSAs:
Convert top-performing content from your existing Expanded Text Ads into distinct RSA headlines and descriptions.
Ensure there are at least two to three Responsive Search Ads in all of your ad groups.
Include top-performing keywords and clear calls to action within your headline and description assets.
Create at least 11-15 headlines and use a combination of short and long headlines to maximize character count across all devices.
Make the content as distinct as possible:
Avoid repetitive language
Create unique headlines
Consider additional product or service benefits or features
Test a clear call-to-action
Include shipping and return information
Take RSAs to the next level by customizing your assets:
Ad customizers
Countdown timer
Location insertion
Dynamic keyword insertion
Place the Universal Event Tracking (UET) tag across your website with conversion tracking enabled to provide stronger optimization signals for the RSA algorithm.
Review asset strength, combination reports and other details within the Assets tab to optimize your assets with low impressions.
Responsive Search Ads have taken center stage in search campaigns. If you were sleeping on RSAs before, it is time to wake up and take notice. Start creating RSAs to launch alongside your existing Expanded Text Ads today. Happy ad testing, everyone!
Knowledge panels are one of the most coveted, yet mysterious elements in organic search.
Brands desire to have their own robust Knowledge Panel entry, but are left with little to no control over what appears in them.
By this point, we should all have a basic understanding of entities within Google’s Knowledge Graph. Consider that required reading for this article.
Where does Google pull entity data from?
We all know that Google pulls information from their Knowledge Graph for knowledge panels, but where do they pull information for the Knowledge Graph?
Technically, Google can use information from any crawlable website for their Knowledge Graph. However, we most often see Wikipedia as the dominant source of information.
The types of websites Google likes to pull from are typically directory-style websites that provide information that is:
Accurate.
Structured.
Consistent.
Jason Barnard’s Kalicube has an awesome resource that tracks entity sources for the past 30 days. I referred to this list and many of his articles for guidance on building my knowledge panel and personal entity.
Why is Wikipedia so prolific?
Google tends to use Wikipedia so heavily for a few reasons:
It’s heavily moderated and difficult to get an entry approved.
The content is well structured and easy for search engines to understand.
It’s a highly trusted resource.
While Wikipedia has skeptics reminding us that anyone can edit an entry, a heavy amount of moderation and editing still takes place on Wikipedia. Given that it’s also a fairly neutral/unbiased source of information, that gives Google all the more reason to trust it.
So if it’s so difficult to get an entry, why do so many SEOs only focus on getting a Wikipedia page as their way into the Knowledge Graph?
Well, the answer is that once you have a Wikipedia page, it’s almost a guaranteed entry. However, this is a mindset we need to break, because by now, we should all know that there are no guarantees in SEO.
Sure you can definitely pursue a Wikipedia page for your own brand, but just make sure to diversify your tactics and don’t just focus on that as your sole strategy.
How long does it take to earn a Knowledge Graph entry?
Don’t say it depends, don’t say it, don’t say it. Okay, so it is different for everyone. For me, it took about a year since the beginning of my efforts for mine to appear.
It all depends on how hard your brand is working and whether or not your brand deserves one.
Did I try that hard? Not really.
Did I deserve one? Not at all.
But based on the specific steps I took to market myself in the industry, I just so happened to earn a Knowledge Panel in the process.
I never thought I’d actually get one, but decided to run a series of tests to see if it would actually work, and to my surprise it did.
The specific steps I took to earn my knowledge panel
Okay now that you’ve probably scrolled past all of my intro content, let’s get to what you came here for. What specifically did I do to earn my Knowledge Panel entry and get established in Google’s Knowledge Graph?
Here are the specific steps I took in order.
1. Established entity home
The first step is to establish your root or home of your entity. This could be your personal website, brand’s page, author page, or anything that is the truest source of information for the entity. For me, I chose my personal website’s homepage for my entity home.
On my homepage, I did two specific things to help search engines:
Created ‘About Me’ Content
I created a one-sentence “about me” that I planned to use on all bio information across the web. Almost all of my personal bios on different websites I’m featured on start with this sentence. This creates consistency on who I am and what I do.
Create bulleted list of work
Having a short, easy to crawl, list of what I do helps create a connection to myself and other entities. My hope was Google would understand that I could be found on those other websites and better understand the relationship between myself and those entities. More on this in the schema section.
2. Industry authorship
For the past four years, I’ve been featured on dozens of podcasts and written plenty of articles for Search Engine Land, Search Engine Journal, OnCrawl, and many mory!
All of my features come with an author page, which has a list of all my articles for that site as well as Person schema for that site.
Additionally, all of my author pages contain a link back to my entity home, which is critically important for building your brand’s entity relevancy.
3. Consistent schema
Schema markup is the connective tissue that brings all of my authorship together. On my entity home, I ensured that I have robust schema markup.
The most important thing to include in the schema markup is the SameAs data which I directed to all of my most important features on the web. I ensured to add SameAs links to any sources that I’ve seen generate entities in the past.
Below is a screenshot of what you’ll see if you run my personal website through the Schema Markup validator.
The specific schema type I chose was Person, as this was most accurate to myself. If you’re creating an entity for your business or brand, try to choose the schema type that’s most accurate to your business.
Typically, I create schema from scratch for all of my clients. However, Yoast’s author/person schema provided exactly what I was looking for and included one important feature.
What Yoast did for me was instead of making a generic Organization schema type for my website, I marked my website as a Person.
Within the specific settings, I pasted all of my important links into the contact info fields. Please note that other than Twitter, you can paste any link in those fields.
4. Consistent linking
Schema plays a huge factor in creating an interconnected web of consistent information for Google’s Knowledge Graph. However, external links provide even greater trust signals.
On my website, I have a collections page that links out to all of my important work. It’s like a mini CV of my work for anyone who wants to work with me.
However, you can’t just link out to other places on your website, you need established entities linking back to you.
That’s why all of my featured podcasts and author pages have a link back to my website. Not only are they linking back to my website, they’re all linking to my homepage, which I’ve established as my entity home.
5. Directories
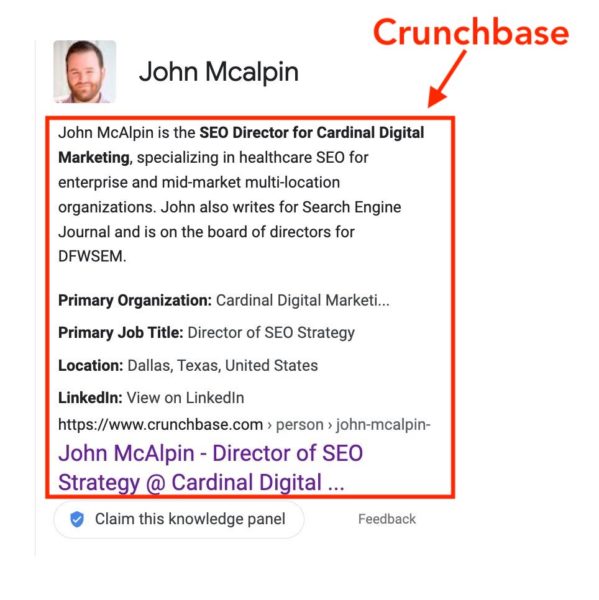
This can definitely help get an easy foot in the door for many people and brands trying to get established with their own knowledge panel. One of the biggest directories that I recommend getting established in is Crunchbase.
In fact, Crushbase is what was listed as the source data during the first iteration of my knowledge panel.
I’ve seen many startups get their first knowledge panel entry through Crunchbase and it seems to be a consistently high source for Google to rely on. This is because Crunchbase has some verification processes that make it slightly more challenging to create spam in bulk.
When getting started with building out your directories, focus on the niche ones that are most relevant to your industry. This will go a lot farther for you than Crunchbase or any other big ones.
The different iterations my knowledge panel has shown
Over the course of about 1-2 months, Google has used a variety of different sources to feed my knowledge panel. It’s been very interesting to see how it’s evolved over such a short amount of time. I’ve even had my own article carousel which has since disappeared.
First iteration: All crunch, no flavor
At first, Crunchbase was the source of my entire knowledge panel entry. Something I found amusing is that there’s no link for my LinkedIn page, it’s just the anchor text on Crunchbase.
This was a great win for me and I was pleased with how structured the knowledge panel was.
I tested a few queries to see how my entity data would appear as a zero-click result.
Testing searches: “Who is John McAlpin?”
This result was a little disappointing as it brought up a different John McAlpin who was referenced in a press release. However, I did see my entity in a side panel, which was both surprising and exciting.
Testing searches: “Where Does John McAlpin Work?”
This was a much more accurate result, but also a surprising one. If Crunchbase was fueling most of my knowledge panel data, why was Google showing Search Engine Journal as the source for this featured snippet?
We could speculate all day on our theories of how Google came to this decision, but I was just glad to see a more accurate result here.
Second iteration: Images getting comical
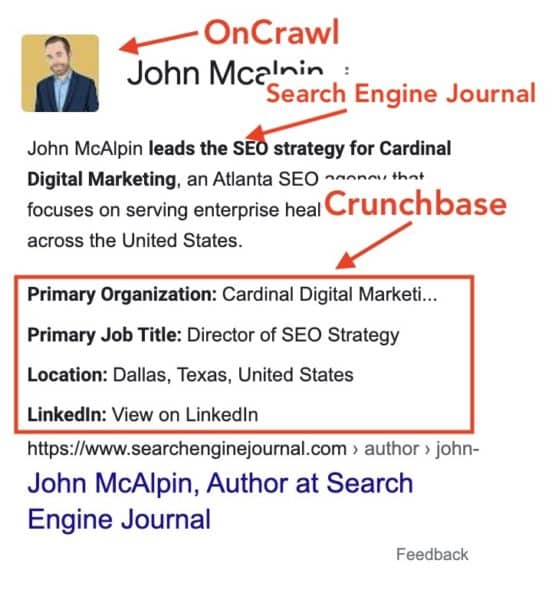
A few weeks after the first sighting of my Knowledge Panel, I see a few interesting updates:
My image changed to a caricature that I used on one of my OnCrawl articles.
The “about” content changed to my author bio from Search Engine Journal
Summary data remained from Crunchbase
Source data label changed to my Search Engine Journal author page.
Third iteration: Image correction
Unhappy with my image being a cartoon for my professional headshot, I submitted feedback to update the image. I chose my image from Search Engine Land and sure enough it updated it about two weeks later.
Key takeaways
When seeking to earn your own knowledge panel, it’s important to keep in mind a few things.
It may not happen at all. You have no control over what Google displays in its results. All you can do is try to send the right signals consistently and hope that it pays off.
If it does happen, it will take time. It took me longer than a year for my knowledge panel to show up. Large organizations that have aggressive PR firms have a higher chance of showing up sooner, but even that isn’t a guarantee.
Consistency is key. Once you establish the signals you want to send, be consistent in that. As you could see in my second iteration, I wasn’t consistent in my choice of imagery and that messed up how I wanted my knowledge panel to appear.
Have patience. Just like all other factors in SEO, it takes time.
QR codes are shaking up the marketing world (did you see that Coinbase Superbowl commercial?). This seminar will teach you everything you need to know about how QR codes can be used to unlock mobile engagement and revenue, channel attribution, and first-party data in a cookieless world.
Join QR marketing expert Brian Klais, CEO of URLgenius, to learn enterprise-grade QR strategies and best practices you won’t hear anywhere else and change how you think about QR code opportunities.
The most significant overhauls were to Google’s definitions of YMYL (Your Money, Your Life), and the extent to which E-A-T matters as a matter of page quality.
Google provided new, clear definitions for what it means for content to be YMYL, mostly framed around the extent to which the content can cause harm to individuals or society. Google also provided a new table establishing clear examples of what it means for content to be YMYL or not.
In the new guidelines, Google also explained that for highly YMYL content – E-A-T is crucial above all other factors. It also explained that it’s possible to have low-quality content on otherwise trustworthy and authoritative sites.
Your Money, Your Life (YMYL) Topics – Section 2.3
Google completely reframed its definition of YMYL (Your Money, Your Life). In the previous version of the Quality Rater Guidelines, YMYL topics were broken down into the following categories:
News and current events
Civics, government and law
Finance
Shopping
Health and safety
Groups of people
Other
Google completely removed these categories.
The new version of the Quality Rater Guidelines now defines YMYL by its potential to cause harm.
Topics that present a “high risk of harm,” can significantly impact the “health, financial stability, or safety of people, or the welfare or well-being of society.”
Google then defines who may be harmed by YMYL content, including the person viewing the content, other people affected by the viewer, or groups of people or society as a whole. This could potentially be in reference to violent, extremist or terrorist content.
Google then defines YMYL topics as either being inherently dangerous (violent extremism), or harmful because presenting misinformation related to the topic can be harmful. For example, providing bad advice related to heart attacks, investments or earthquakes could cause harm to the user.
Instead of listing individual categories that may be considered YMYL, as in previous versions of the guidelines, Google now asks quality raters to think of YMYL in terms of four types of harm YMYL content can cause for individuals or society:
Health or safety
Financial security
Society
“Other”
In another new addition, Google claims that a “hypothetical harmful page” about a non-harmful topic, such as the “science behind rainbows,” is technically not considered YMYL. According to their updated definition, the content must have the potential to cause harm or otherwise impact peoples’ well-being.
In another big update, Google claims that many or most updates are not YMYL because they do not have the potential to cause harm.
Google also stated for the first time that YMYL assessment is done on a spectrum.
To clarify these new statements, Google provided a new table on page 12 of the guidelines, which specifically delineates the types of topics that Google considers YMYL or not, with clear examples.
Low Quality Pages – Section 6.0
Google revamped its definition of what it means to be a low-quality page.
In a previous version, Google claimed a page may be low quality, in part, because the creator of the main content may lack sufficient expertise for the purpose of the page. This statement was deleted.
Google now expands upon the role of E-A-T in determining whether a page is low-quality in three new paragraphs:
Google explains that the level of E-A-T required for the page depends entirely on the topic itself and the purpose of the page.
Topics that only require everyday expertise don’t require that the content creators provide information about themselves.
Google also suggests that a low-quality page can exist on an otherwise authoritative website, like an academic site or a government site. The topic itself of the page is where YMYL comes into play – if the content could potentially cause harm to the user, quality raters must evaluate that aspect when determining the quality of the page.
Lacking Expertise, Authoritativeness, or Trustworthiness (E-A-T) – Section 6.1
Google added a bullet point in its definition of what it looks like to lack E-A-T when determining whether a page is low-quality:
“Informational [main content] on YMYL topics is mildly inaccurate or misleading”
In another new addition, Google once again repeated that the level of E-A-T a page requires depends on the purpose and the topic of the page. If the page discusses YMYL topics (and potentially presents harm to the user or others), E-A-T is critical.
Even if the website has a positive reputation, if there is a significant risk of harm, the page must be rated as low quality.
Lowest Quality Pages – Section 7.0
Google inserted a new section in the “lowest quality pages” section suggesting that even authoritative or expert sources can still present harmful content. This could include hacked content or user-uploaded videos.
Just because content exists on a site that otherwise demonstrates good quality, if the content itself is deceptive, harmful, untrustworthy or spam, this still requires a “lowest quality” rating.
Google’s new document about Search Quality Rater Guidelines
In addition to updating the Search Quality Rater Guidelines, Google also published a new resource describing how the Search Quality Rater Guidelines work. This resource includes sections about how search works, improving search and the quality rating process.
This document provides the most comprehensive overview to date of the role Google’s quality raters play in evaluating how well Google’s proposed changes are in line with Google’s own quality guidelines.
Google also provides information about who the raters are, where they are located and how the rating process works.
Why these changes matter
For those interested in understanding how Google defines the concepts of YMYL and E-A-T, Google’s updated Quality Rater Guidelines provide some new guidance about what they aim to achieve with their algorithm.
As opposed to thinking about YMYL in terms of business or content categories, Google asks raters to think about the extent to which content can cause harm to users.
Google also clarified that everyday expertise is sufficient for many types of content, but E-A-T is of the utmost importance when the content qualifies as YMYL (it has the potential to cause harm to individuals or society, or can affect one’s financial wellbeing, health or safety).
The guidelines break down into three key areas: query understanding, page quality rating and page match rating.
Query understanding. This is all about figuring out the intent behind the user’s search query. Neeva breaks down the types of queries into the following categories:
How to: User is searching for instructions to complete a task.
Error/troubleshooting: Something went wrong, user is searching for a solution.
Educational/learning: Who/what/where/when/why.
Product seeking/comparison: User is searching for a new product/tool or comparing products/tools.
Navigational: User is searching for information on a person or entity.
Ambiguous: Unclear what the user is searching for.
Page quality rating. Neeva has broken down pages into three levels of quality: low, medium and high. Advertising usage, page age and formatting are critical elements.
Here’s a look at each:
Low quality:
Dead pages
Malware pages
Porn/NSFW pages
Foreign Language
Pages behind a paywall
Clones
Medium quality:
3+ ads when scrolling / 1 large banner ad / interstitial or video ads
Page is 5+ years old
Page loads slowly
Format of page makes it difficult to extract information
Forked github repo
Pages behind a login or non-dismissable email capture
Question page with no response
High quality:
Meet the age criteria
Meet the ads criteria
Be well formatted
Page match. Neeva has its raters give a score to the match between the query and a webpage, between 1 (significantly poor) to 10 (vital). Here’s that scale:
Significantly Poor Match. Does not load, page is inaccessible.
Especially Poor Match. Page is wholly unrelated to the query. Missing key terms.
Poor Match. Page may have some query phrases, but not related to the query.
Soft Match. Page is related to query, but broad, overly specific, or tangential.
On Topic but Incomplete Match. Page is on topic for the query, but not useful in a wide scope, potentially due to incomplete answers or older versions.
Non-Dominant Match. Page is related to the query and useful, but not for the dominant intent shown.
Satisfactory Match. This page satisfies the query, but may have to look elsewhere to round out the information.
Solid Match. This page satisfies the query in a strict sense. There is not much extra, or beyond what is asked for.
Wonderful Match. This page satisfies the query in a robust, detailed sense. It anticipates questions/pitfalls that might come up and/or adds appropriate framing to the query.
Vital Match. This is a bullseye match. It is not available on all queries. The user has found exactly what they were looking for.
Read the full guidelines. They were published on the Neeva blog, here.
Why we care. It’s always smart to understand how search engines assess the quality of webpages and content, and whether it matches the intent of the search. Yes, Neeva has a tiny fraction of the search market share. But the insights Neeva shared can provide you some additional ways to think about, assess and improve the quality of your content and webpages.
Google has updated its search quality raters guidelines today, this is an update from the October 2021 update. You can download the full 167-page PDF raters guidelines over here. This version has refreshed language in the new overview section, a refined YMYL section, with more on low-quality content, YMYL, E-A-T, and more.
What is new. Google posted these bullet points on what is new on the last page of this PDF.
Refreshed language to be aligned with the newly published Search Quality Rater Guidelines: An Overview
Refined YMYL to focus on topics that require a high level of accuracy to prevent significant harm; added a new table of examples and refreshed existing examples
Added clarifications to Low and Lowest Page Quality sections to emphasize that the type and level of E-A-T depends on the purpose of the page, and that low quality and harmful pages can occur on any type of website
Refactored language throughout to be applicable across all devices types
Minor changes throughout (updated screenshots; removed or updated outdated examples and concepts; removed user location when irrelevant; etc.)
Also, the previous version was a 171-pages, this revised document is 167-pages.
Why we care. Although search quality evaluators’ ratings do not directly impact rankings (as Google clarified in the document), they do provide feedback that helps Google improve its algorithms. It is important to spend some time looking at what Google changed in this updated version of the document and compare that to last year’s version of the document to see if we can learn more about Google’s intent on what websites and web pages Google prefers to rank. Google made those additions, edits, and deletions for a reason.
You can download the 167-page PDF raters guidelines over here.
Entity search can be a massive competitive advantage. But you first need to build your entity-based strategy.
This article will cover how to create a robust entity-first strategy to help our content and SEO efforts.
Most common challenges search and content marketers face
Relevant, topical content, discovery based on customer intent is still the biggest challenge we face as search marketers.
Content relevancy, in my mind, means the content is personalized, must tell a story, should be scannable, readable, provides images, and the layout can be consumed on any device.
Here are five outcomes we aim to accomplish with content:
Discovery: Ensure content is discoverable and available across various customer touchpoints.
Relevancy: Ensure content meets all the searchers’ needs and contains all topics and sub-topics that a searcher cares about, is easy to read and understand and tells a story.
Measurability: Content aligned with overall SEO strategy and is scalable and measurable.
Experience: Content delivers a great user experience and is scannable.
Engagement: Helps drives engagement and guides the visitors to the desired goals – sign-ups, purchases, form fills, calls, etc.
The most common struggle we all face is determining what type of content to create or add.
Aligning strategies with search engines
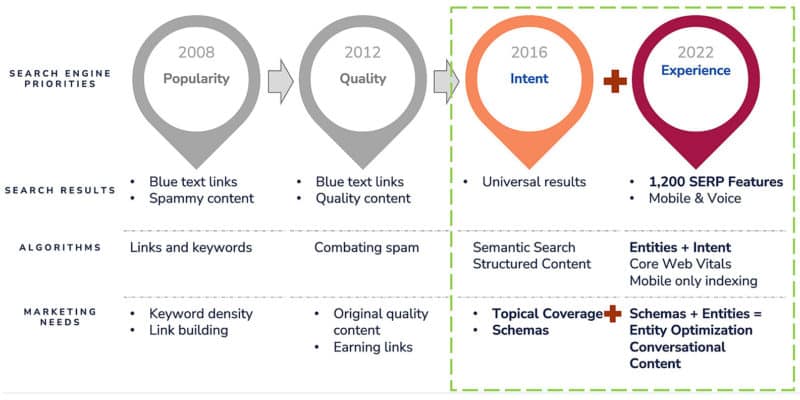
Search engines are evolving and content marketing strategies need to align across all verticals from popularity and quality to the intent behind the query and the overall page experience.
Search engine priorities, results, algorithms and needs have evolved over time.
Evolution of search engines and impact
As users search on screenless devices and spoken queries increase, search engines use artificial intelligence and machine learning to try and replicate how humans think, act and react.
Search engines must decode a sentence (or paragraph) long query and serve results that best match it. This is where entities come in.
Entities are things search engines can understand without any ambiguity independent of language. Even when a website has a wealth of content, search engines need to understand the context behind it, identify the entities within the content, draw connections between them and map them to the query of the searcher.
Deploying schemas and marking up the entities within your content gives search engines the context and helps them understand your content better.
A convergence of technology and content
Content, where entities are not marked with schemas, tends to underperform.
Similarly, deploying schemas on content that does not contain all the relevant entities or does not provide all the information will also not have maximum impact.
Entity optimization uses advanced nested schemas deployed on content that meets the searchers’ needs and contains all the relevant topics and entities.
Let’s use a live project as an example and show what we accomplished for one of our clients.
8 steps to developing an entity-first strategy
We deployed the eight steps given below as an entity-first-strategy for one of our client in the health care vertical to help them get the best topical coverage and visibility. We started by identifying the most relevant schema in their industry followed by determining the gaps within their content for both schema and entities.
Eight steps for an entity-first strategy
1. Identified schema vocabulary
We created a list of all applicable schemas in the healthcare industry.
2. Determined the schema gaps
We identified the schema gaps by comparing the current site content against the applicable schemas.
3. Mapping schema
Once we identified the schema gaps, we identified the most relevant pages to deploy the unused schemas.
4. Market opportunity and potential sizing
We used in-depth keyword research and analysis of current content performance.
Map content based on informational, navigational and transactional content.
It is critical to see how your current branded and non-branded content is performing and what your focus should be based on business goals.
Market opportunity and potential sizing
We identified the pages that could see the most impact and potential from topic, entity, and schema optimization.
5. Map topic gaps
Once we identified the best potential pages, we cross-referenced the gaps in the content by analyzing the topics and entities covered by other ranking websites.
6. Identify Content Opportunities
We enhanced the page architecture by adding relevant content elements, such as images, headings and lists.
Page layout showing schema and content opportunities
Topic/entity gaps covered:
care plan
Treatment
Treatment center
ABA services
Behavior technician
Autism spectrum disorder
BCBA
ABA therapist
ABA services
Schema gaps covered:
Medical organization
SiteNavigationElement
Medical clinic
availableService
hasmap
FAQ
ItemList
7. Content enhancement
Optimized the content by incorporating missing topics and entities
8. Create better than the best website page
We then created the perfect in-depth page, rich with relevant topics the target audience is searching for.
Measuring entity strategy Impact
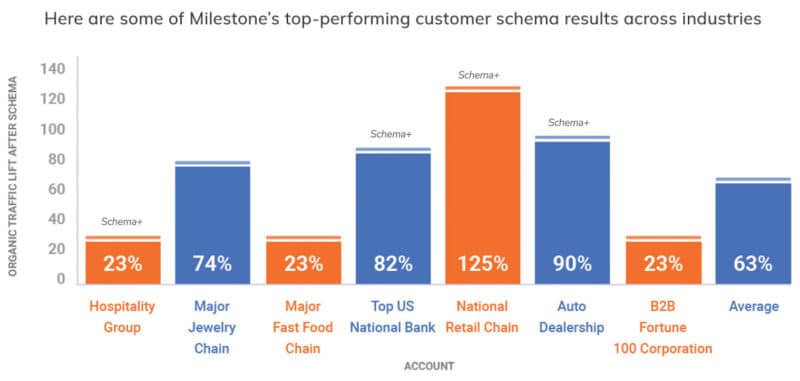
When we measured the impact of adding entities and schema into our strategy for this healthcare company, we saw a 66% lift in visibility and inclusions in rich results.
Overall impact of new page.
While the above image is just one example of the impact entities and schema can have, you can see below how many different industries benefit by deploying schema and entity coverage.
Impact of schemas across various industries.
Key takeaways
Creating content is more than writing. It is robust when you add in all the elements from design, development, topical entity coverage and schema. All these elements need to align to give optimum results.
Keeping organization in mind, cluster pages of relevant content and connect them through pillar pages, ensuring to take advantage of the interlinking opportunities.
Treat each page as the main category page with several relevant pages linked. Adding interlinking helps in discovery and relevancy.
Once you have an entity-first strategy for content, you need to think about how to scale the process of:
Understanding the entity.
Tagging schema.
Pruning broken links or errors as they come.
Continuing to add more meaningful content.
Entity optimization frameworks for large enterprise sites
In my next article, we will explore how you can deploy, measure and report performance, enhance where needed and scale your entity-first strategy.
Google’s Privacy Sandbox initiative began with the intent to create technology to protect people’s privacy. Part of that initiative was to reduce cross-site and cross-app tracking by eliminating third-party cookies. Today it was announced that the initiative has been delayed and developers are aiming for a Q3 2023 launch. Google developers also predict that it will start phasing out third-party cookies in the second half of 2024.
Why the delay. Google says that “consistent feedback” from developers, marketers, and publishers, and more testing are the reasons for the delays.
The most consistent feedback we’ve received is the need for more time to evaluate and test the new Privacy Sandbox technologies before deprecating third-party cookies in Chrome. This feedback aligns with our commitment to the CMA to ensure that the Privacy Sandbox provides effective, privacy-preserving technologies and the industry has sufficient time to adopt these new solutions. This deliberate approach to transitioning from third-party cookies ensures that the web can continue to thrive, without relying on cross-site tracking identifiers or covert techniques like fingerprinting.
Anthony Chavez VP, Privacy Sandbox
Early testing for developers. Developers can test the Privacy Sandbox API now, and trials will be released in early August as they’re released to “millions of users globally, and we’ll gradually increase the trial population throughout the rest of the year and into 2023.”
Read the announcement. You can read the blog post announcement on Googe here, and also visit the Privacy Sandbox website.
Why we care. A bad thing for privacy-conscious consumers. A good thing for advertisers? A lot of advertisers and platforms may have been scrambling to find out of the (sand) box solutions to tracking data since it was expected that cookies would no longer be an option. It looks like we’ll have at least another year to prepare.
Google has begun the rollout of the fourth version of the product reviews update, a search ranking algorithm update targeted at ranking product review-related content on the web that is most helpful and useful to searchers. The first product reviews update was launched on April 8, 2021, the second was launched on December 1, 2021, the third has been released on March 23, 2022, and now the fourth has been released on July 27, 0222. The new is named the July 2022 product reviews update.
Google announced this update on Twitter referencing the standard help document around how to write product reviews.
Google product reviews update. The Google product reviews update aims to promote review content that is above and beyond much of the templated information you see on the web. Google said it will promote these types of product reviews in its search results rankings.
Google is not directly punishing lower-quality product reviews that have “thin content that simply summarizes a bunch of products.” However, if you provide such content and find your rankings demoted because other content is promoted above yours, it will definitely feel like a penalty. Technically, according to Google, this is not a penalty against your content, Google is just rewarding sites with more insightful review content with rankings above yours.
Technically, this update should only impact product review content and not other types of content.
What is new. Unlike the March product reviews update, it seems nothing specifically changed with any ranking criteria with this update. Google is likely just refreshing the algorithm and making slight adjustments.
The rollout. This rollout will take “take 2-3 weeks to complete,” Google said. These, and core updates, normally take a few weeks to roll out, so that should be no surprise. You should expect the bulk of the ranking volatility to happen in the earlier stages of this rollout.
What is impacted? Google said this update may in the future impact those who “create product reviews in any language,” but Google said the initial rollout will be “English-language product reviews.” Google added they have seen “positive effects” from this update in the past and the search company “plans to open up product review support for more languages” in the future.
Previous advice on the product reviews update. The “focus overall is on providing users with content that provides insightful analysis and original research, content written by experts or enthusiasts who know the topic well,” Google said about this update. That is similar advice to the core update recommendations mentioned above, but here is a list of “additional useful questions to consider in terms of product reviews.” Google recommends your product reviews cover these areas and answer these questions. Do your product reviews…
Express expert knowledge about products where appropriate?
Show what the product is like physically, or how it is used, with unique content beyond what’s provided by the manufacturer?
Provide quantitative measurements about how a product measures up in various categories of performance?
Explain what sets a product apart from its competitors?
Cover comparable products to consider, or explain which products might be best for certain uses or circumstances?
Discuss the benefits and drawbacks of a particular product, based on research into it?
Describe how a product has evolved from previous models or releases to provide improvements, address issues, or otherwise help users in making a purchase decision?
Identify key decision-making factors for the product’s category and how the product performs in those areas? For example, a car review might determine that fuel economy, safety, and handling are key decision-making factors and rate performance in those areas.
Describe key choices in how a product has been designed and their effect on the users beyond what the manufacturer says?
Provide evidence such as visuals, audio, or other links of your own experience with the product, to support your expertise and reinforce the authenticity of your review.
Include links to multiple sellers to give the reader the option to purchase from their merchant of choice.
Google added three new points of new advice for this third release of the products reviews update:
Are product review updates relevant to ranked lists and comparison reviews? Yes. Product review updates apply to all forms of review content. The best practices we’ve shared also apply. However, due to the shorter nature of ranked lists, you may want to demonstrate expertise and reinforce authenticity in a more concise way. Citing pertinent results and including original images from tests you performed with the product can be good ways to do this.
Are there any recommendations for reviews recommending “best” products? If you recommend a product as the best overall or the best for a certain purpose, be sure to share with the reader why you consider that product the best. What sets the product apart from others in the market? Why is the product particularly suited for its recommended purpose? Be sure to include supporting first-hand evidence.
If I create a review that covers multiple products, should I still create reviews for the products individually? It can be effective to write a high-quality ranked list of related products in combination with in-depth single-product reviews for each recommended product. If you write both, make sure there is enough useful content in the ranked list for it to stand on its own.
Not a core update. Google also previously said that product review updates are not the same as core updates. This is a standalone update they’re calling the product reviews update. This is separate from Google’s regular core updates, the company told us. Nonetheless, Google did add that the advice it originally provided for core updates, “about producing quality content for those is also relevant here.” In addition to that advice, Google provided additional guidance specific to this update.
Why we care. If your website offers product review content, you will want to check your rankings to see if you were impacted. Did your Google organic traffic improve, decline, or stay the same?
Long term, you are going to want to ensure that going forward, you put a lot more detail and effort into your product review content so that it is unique and stands out from the competition on the web.
Also, those impacted by previous core updates, that put in the work, may be rewarded by this July 2022 product reviews update.
Providing a memorable and consistent customer experience is more crucial and challenging than ever.
Businesses must consistently adapt by adopting new technologies, reliably benchmarking performance, and listening to critical customer feedback to deliver unparalleled value and achieve positive growth.
Highly personalized, seamless experiences are at the forefront of customer expectations, which means businesses must evolve to provide connected journeys every step of the way. A comprehensive set of solutions that seamlessly mix local marketing and customer experience technology wasn’t available; until now.
Local marketing and customer experience technology power unparalleled local experiences
Every customer’s experience begins the moment they discover your brand. A customer may conduct an online search to learn more about a business or read customer reviews. The experience doesn’t end once a purchase is made. Customers have the power to be a brand’s best advocate or its most vocal critic – either way those experiences are invaluable. Having the tools accessible to better understand your customers’ pain points allows your business to engage more effectively at every touchpoint and build a loyal following.
Forsta, the global leader in customer experience (CX), employee experience (EX) and market research, is combining capabilities with Rio SEO, the industry-leading local marketing platform for enterprise brands. Together, the combined technologies power a seamless customer experience solution, enabling brands to engage customers throughout the entire buyer’s journey, from discovery to purchase and through to brand reputation and advocacy.
Rio SEO and Forsta are reshaping the local search landscape by bringing to market the industry’s only end-to-end local marketing and customer experience solution for global enterprise brands.
We call this unique combination Local Experience (LX), and it’s a game-changer for enterprise brands looking to optimize their business and deepen customer relationships.
Rio SEO’s Open Local Platform supplements Forsta’s Human Experience platform by enabling customers to seamlessly expand their customer experience programs into the discovery and consideration phases earlier in the purchase funnel and through to the post-purchase brand reputation and advocacy stage. Rio SEO’s local marketing solutions drive discovery and sales at the local level, at scale and complement Forsta’s technology to support customer engagement and loyalty post-sale.
Forsta’s market research and customer experience solutions, recognized as a Leader in the 2021 Gartner® Magic Quadrant for Voice of the Customer, take you from data, to insight, to action by helping you understand your customer, see who they really are, and better respond to their needs.
Enhance your discoverability, attract new customers, and build long-lasting relationships with Forsta and Rio SEO’s LX solutions. Visit rioseo.com/forsta to learn more.
Many of the same concepts that you may be used to from Universal Analytics exist in Google Analytics 4. There are, however, several new concepts to GA4.
This article will detail some familiar and not-so-familiar concepts that GA4 brings to the table.
If you’re new to GA4, I’d encourage you to first check out this article to get up to speed on some of the differences between Universal Analytics and GA4, otherwise, read on.
Similar concepts, slightly different application
Let’s start with the familiar by looking at concepts that exist in both Universal Analytics and Google Analytics 4.
But first, a small caveat: Universal Analytics has the ability to filter data in a robust manner at the view level. Google Analytics 4 only has a few filters currently available at the property level (there are no views in GA4), and so any differences you may see in your data should keep your current UA filters in mind.
With that being said, let’s dive into some familiar metrics:
Users
In Universal Analytics, the Users metric looks at the total number of users during the selected time period. In Google Analytics 4, the Users metric is actually split into two: Total Users and Active Users.
Active Users is the primary Users metric in GA4 and what you will see used in the default reports within the GA4 UI. Active Users are the users during the time period that have had an engaging session on your site in the past 28 days.
For most sites, these numbers will likely be close. But if you see differences between UA and GA4, this could be a reason why.
Sessions
In Universal Analytics, a session is a period of time that a user is actively engaged with your site. There are several things that may end a session, such as an inactive 30-minute time period, a change of UTMs or the session breaking at midnight.
In Google Analytics 4, a session is determined via the session_start event. GA4 does not restart a session with a change of UTMs and does not break the session at midnight, but it does look for an inactive time period of 30+ minutes to restart the session.
Due to the varying ways a session is started between the two property types, total session counts may look quite different between UA and GA4 depending on how often you may have been subject to the restart criteria in UA – definitely keep this in mind as you compare numbers between the two platforms.
Pageviews
These should be pretty similar concepts between UA and GA4. The biggest difference here is that if you are using GA4 to track both app and web, GA4 combines the pageview and screenview metrics into Views. If you are only tracking web for both UA and GA4, the numbers should look pretty consistent between platforms.
Less familiar concepts
Conversions
Conversions are the new Goals, but please note that they are not equal.
A Conversion in GA4 is simply an event that has been marked as a conversion. This is as simple as toggling a button on or off to note that the event is now a conversion.
Two main things to be aware of here for the differences between Goals in UA and Conversions in GA4:
Goals in UA counted only once per session. That means that even if the goal occurred multiple times in the same session, for example, a goal fired each time a form was completed, and a particular user completed three forms in one session, it would only count as one goal completion. In GA4, the conversion will fire every time the event has been satisfied, so in the same example, it would count as three conversions in the same session.
In UA, you could create a goal based on several factors: destination, duration, pages/screens per session, event and smart goals. In GA4, Conversions can only be based on events. This means that you’ll need to get creative, such as creating an event for a specific destination/page, to convert some of your goals to events. Audience Triggers are another thing to consider for things like duration goals.
Engaged sessions
This is a new concept to GA4. An Engaged Session is defined as “the number of sessions that lasted longer than 10 seconds, had a conversion event, or had at least two pageviews or screenviews.”
This new metric allows you to get a better understanding of the sessions that are higher quality and/or more engaged on your site content. Engagement Rate is the percentage of Engaged Sessions. The inverse of Engagement Rate is Bounce Rate (see below).
A blending of the two
Bounce Rate
I need to start this one off by saying that I have never been a fan of bounce rate (or time on site metrics for similar reasons). I think that there are many places where the bounce rate calculation in Universal Analytics can lead you astray in your analysis. Simo Ahava even has a funny little website dedicated to showing you what a good bounce rate is.
But I do recognize that some businesses (especially verticals like Publishers) rely heavily on Bounce Rate. And I know SEOs tend to like this metric.
Google recognizes the need for this metric too. That is why just this month, they’ve released Bounce Rate back into the wild of GA4 (it had previously been considered a deprecated metric for GA4/wasn’t built into GA4 initially).
Here is where I need to stress that this is NOT the same bounce rate that you had in Universal Analytics.
Not.
At.
All.
In Universal Analytics, Bounce Rate was “the percentage of single-page sessions in which there was no interaction with the page.” Every “bounced” session had a duration of 0 seconds for the total time on site calculation. This meant that even if a user came to your website, hung around for 5 minutes reading every word on your home page, but didn’t click on anything or cause any other event or pageview to trigger, they would be considered a bounce.
To say this metric was flawed is an understatement.
In GA4, Bounce Rate is a simple calculation that is the inverse of Engagement Rate. Earlier, I mentioned “Engaged Sessions” – 10 seconds or more than one event or pageview. These are the basis of Engagement Rate. This means that Bounce Rate is the percentage of sessions that are considered to be not engaged.
Why does this matter?
Bounce Rate is now a much more useful metric to show you how many people did not engage with your website. The people who came, read everything on your homepage for 5 minutes and then left are now considered an engaged session, so they will not be counted as a bounce.
While imperfect, it’s a much better definition of what a bounce actually is, helping you as the analyst to better understand who is and who is not engaging with your site content.

























 for Voice of the Customer, take you from data, to insight, to action by helping you understand your customer, see who they really are, and better respond to their needs.
for Voice of the Customer, take you from data, to insight, to action by helping you understand your customer, see who they really are, and better respond to their needs.
